

The LSM Tree
The core of the database is the LSM tree. This is a tree that is stored as a mix of on disk and in memory storage. A path for some data being written would be to first go into a memtable (essentially an in memory buffer). Then once this memtable has reached a determined size we write all of this data to an SSTable.
For my memtable I chose to go for a skiplist. To my understanding cassandra uses a Chunked memtable design now but for simplicity I went for the original Cassandra memtable. In case you aren't familiar with a skip list the easiest way to think of it is a linked list that has checkpoints to nodes further down. Which allows for faster searching and insertion.
Once the memtable is full or a flush is triggered we firstly initiate a new memtable to handle the requests that come in while we flush the writes. Then build an SSTable containing the data in the memtable. Alongside the raw data in the SStable file we also create and store a sparse index and a bloom filter
From here the main features to implement are handling concurrency and compaction. Concurrency on the memtable is handled by using a readers-writer lock. Because SSTables are immutable we don't have to worry about write conflicts so multiple threads can read at once. For the compaction we want to specify an amount of sstables we want per level and once we meet that amount we merge them into a new sstable with a new sparse index and bloom filter.
User facing functionality
This entailed creating a database struct that handled all of the configuration, timers, flushes and compactions for the memtable and the sstable. Which means from a user/server perspective all they need to call to the core database is db.Get(...), db.Put(...) or db.Delete(...).
Tuning performance
This was surprisingly fun for me and incredibly interesting to dig into the nitty gritty of not only how to make a noSQL database performant but also to learn about the quirks and techniques in Go lang. I logged and documented my progress in more granular detail in the repo
Performance starting point
As a starting point, with no server overhead the database could handle the following throughput
- Fuzz Testing Workload
- 30% writes 27,725 ops/sec
- 80% writes 138,221 ops/sec
For example using Go lang's pprof Call Graph I could immediately identify that my skip list compare method had some issues
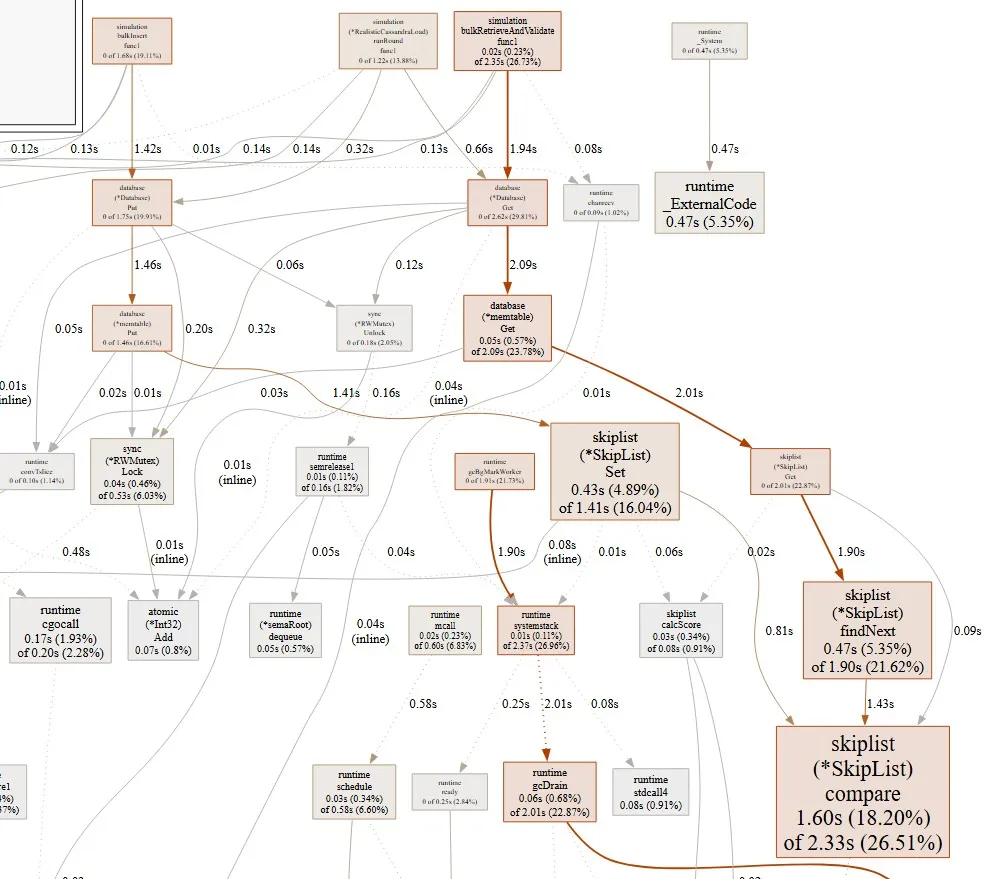
Just looking at a small section of the graph we can see that there quite a few calls causing significant delay. Especially the compare function. In this specific case the comparison wasn't using the most efficient byte comparison. A quick change to use Go's bytes.Compare function and we can see a significant improvement.
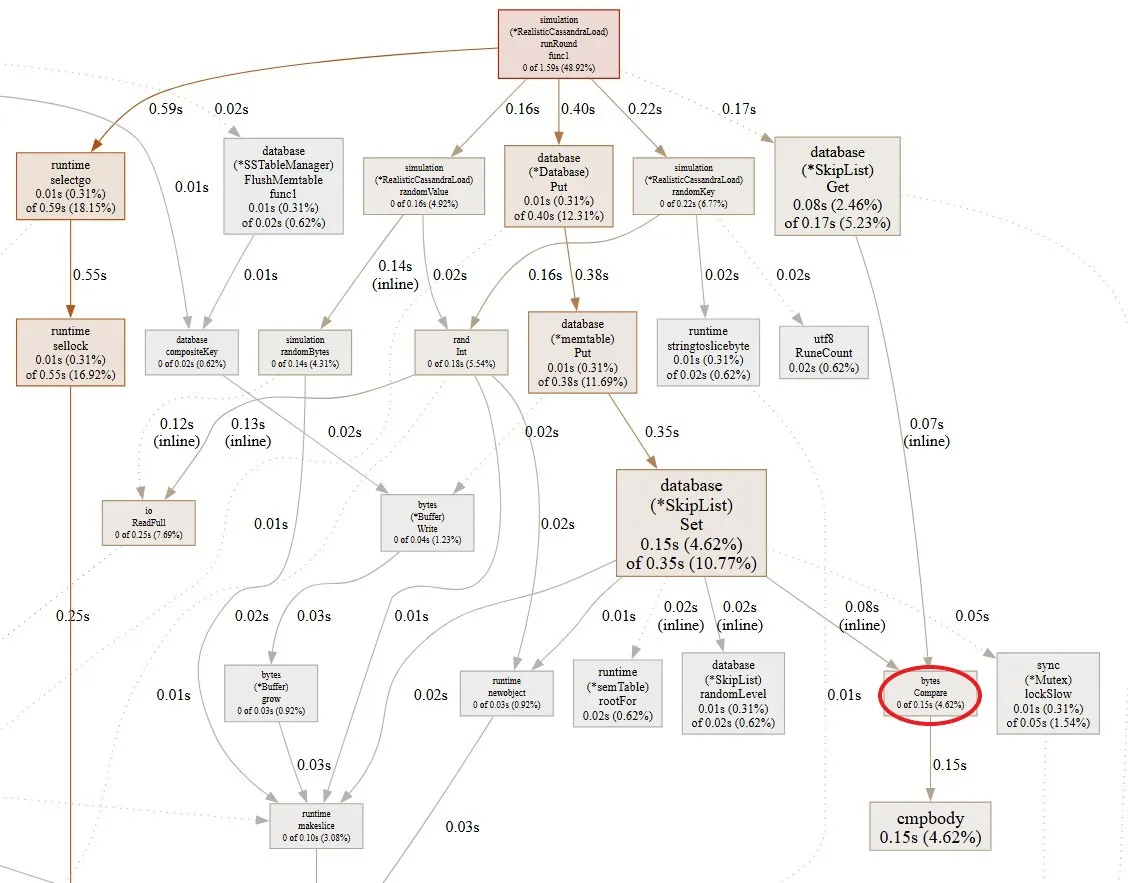
- Fuzz Testing Workload
- 30% writes 672,540 ops/sec
- 80% writes 851,603 ops/sec
Although the comparison remains the largest call in our get method, its share of total time has dropped from 18% to 4%. This significantly improves overall performance because the memtable is mutable. With a Read-Write Lock, slow writes can block for extended periods which destroys our performance especially because every read checks the memtable first before moving onto the SSTables. In contrast, SSTables are immutable, so this kind of blocking is not an issue.
A lot of the implementation here was optimising compaction as it was a large i/o bottleneck as well as improving my skiplist implementation. I made use of pprofs graphs and data to identify where the bottlenecks were for 1 hour simulations and then made changes to the code to improve the performance. I was quite happy with these results because I still needed to add some overhead to ensure ACID compliance.
A Write ahead log
Write ahead loggers are crucial in ensuring your database is ACID compliant. The database could fail Mid-right or pre-flush. Memtables can be configured but can be a few Megabytes in size before they are flushed if not larger. Losing this data on a server crash wouldn't be too ideal so let's prevent that.
Using Uber's Zap logger as a WAL was a simple implementation for me as in combination with Lumberjack we can have automatic new WAL files as they grow in size, file compression and it's on the limit of speed.
The WAL's job is to simple represent the write so the database can replay it to get back to it's original state. We can also make use of Point in Time Recovery. In which we combine Database backups with the WAL to restore very quickly. If the last backup happened 1 hour before the crash. We only need to replay the WAL for the last hour.